인공 지능 정의
과거의 경험을 미래의 결정(예측)에 활용하는 소프트웨어를 디자인하고 연구하는 분야
- 과거의 경험 : 데이터
규칙을 알아내는 방법은 인간이 제시 , 머신이 규칙을 알아내는 과정이 ‘학습(learning)’

주가에 영향을 미치는 요인들을 : 설명 변수
주가 : 반응 변수
learning해서 나오는 값(규칙) : 예측 모델
Learning 방법
- 다양한 학습 알고리즘들이 존재함
-
KNN, SVM, regression, random forest, deep neural network, …
전통적 문제해결 인간 분석자가 데이터를 연구하여 어떤 원리나 이론을 도출 ------------------------------------------------- Machine learning 데이터와 학습 방법을 제시하고 프로그램 스스로 원리나 이론을 도출하도록 함 ## Learning 결과 어떤 방법으로 학습을 시켰는가에 따라 model 의형태는 다양함

정리: Machine learning 은
-
과거의 축적된 데이터를 학습하여 미래를 예측하는 기술
-
주가 예측, 질병진단, 스팸 필터링, 이미지 분류, 번역, …
-
얼마나 정확한 모델을 만드느냐가 관건
-
학습 데이터가 많을 수록 유리

Machine learning 분류
지도학습 (supervised learning) : 설명변수(X), 반응변수(Y) 존재
- 회귀(regression) : Y 가 수치형 (주가, 기온,..)
- 분류(classification) 등 : Y 가 범주형 (정상인/환자, 남/녀, ..)
딥러닝은 주로 지도학습에 해당
비지도학습(unsupervised learning) : 설명변수(X)만 존재
- 군집화(clustering)
강화학습(Reinforcement learning)


학습 모델 개발 과정
지도 학습
- data 준비
- 테이블 형태 (설명 변수와 반응 변수 )
- 이미지
- 사운드 etc.
- data 분류
- 학습용 (training) ( 공부한 자료 )
- 테스트용 ( 공부 안한 자료 )
- training 하고
- 예측 결과
- test 와 training의 결과를 비교 (검증)
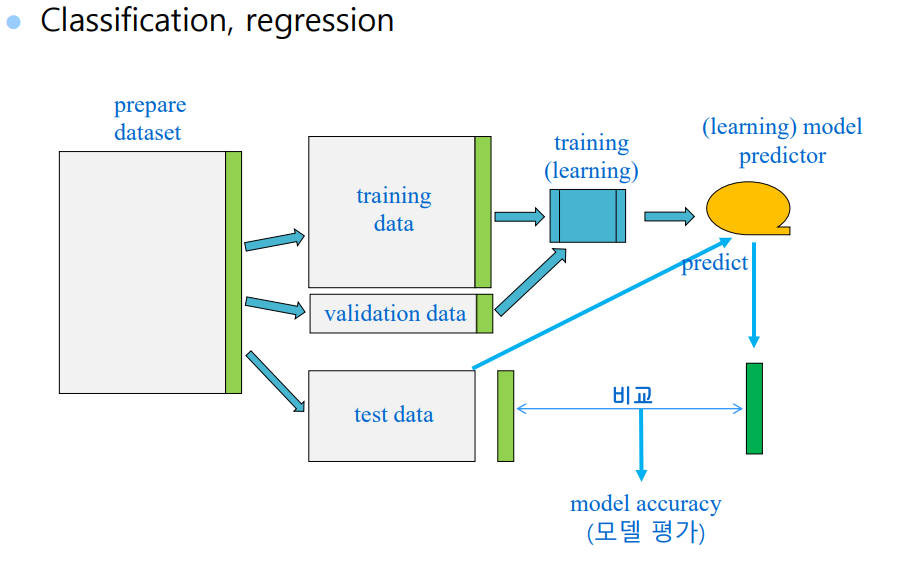
Training data
- 과거 데이터의 역할 Validation data ( 우리는 사용 하지 않음 )
- 학습(훈련)과정에서 만들어지는 모델을 평가하는데 사용
- 더 나은 모델을 만드는데 기여
- 학습방법에 따라 필요치 않은 경우도 있음
Test data
- 미래 데이터의 역할
- 미래 데이터는 없으므로 학습에 사용하지 않은 일부 데이터를 미래의 데이터로 간주
- 미래 예측시 모델이 어느정도의 성능을 보일지를 판단하는 자료
** Train : 50~75%. Test : 10~30%, validation: 나머지

Training accuracy : 모델이 과거의 데이터를 얼마나 잘 설명할 수 있 는지를 보여줌.
Test accuracy : 모델이 미래의 데이터를 얼마나 잘 예측할 수 있는지 를 보여줌
일반적으로 Training accuracy > Test accuracy
scikit-learn
open source Machine learning library in python
- 분류, 회귀, 차원축소등 머신러닝 관련 알고리즘들을 구현
- 데이터 전처리, hyper-parameter tuning, 모델 평가 기능도 제공
install scikit-learn
Anaconda 사용시에는
- Anaconda prompt 에서 conda install scikit-lear
⚫ Numpy 의 배열은 주로 숫자를 저장
⚫ Pandas 의 data frame 은 문자,숫자 컬럼을 함께 저장 가능